
Promettente progetto di ricerca torinese per l’analisi automatizzata testuale delle cartelle cliniche di Pronto Soccorso, per generare alert e individuare lesioni dovuti a violenza non riferiti

Introduzione
Le violenze verso donne in età fertile, minori, anziani, disabili, hanno origine prevalente negli ambiti relazionali e familiari. Le vittime di maltrattamenti ricorrono ai servizi di assistenza sanitaria con maggior frequenza del resto della popolazione. Tuttavia, il problema della violenza in ambito relazionale è caratterizzato da una sistematica sotto-rilevazione, dovuta alla tendenza delle vittime a non esternalizzare le situazioni di abuso compiute da familiari o conoscenti [WHO, 2013].
Ne consegue che nella maggioranza dei casi la violenza non viene riconosciuta come causa dei traumi che hanno condotto una donna a rivolgersi al Pronto Soccorso e non viene quindi annotata all’interno dei referti contenuti nella cartella clinica. Inoltre, le violenze compiute in ambito familiare o da conoscenti tendono ad essere reiterate, determinando accessi ripetuti a setting assistenziali. Se tali situazioni non vengono riconosciute in tempo si può arrivare agli esiti più infausti, come danni permanenti e finanche la morte (ricerche recenti hanno rilevato una significativa associazione tra casi di femminicidio e precedenti accessi in Pronto Soccorso). Il riconoscimento precoce di situazioni ad alto rischio rappresenta quindi un efficace strumento di prevenzione e contrasto delle dinamiche di violenza e di difesa delle vittime. Porre attenzione al riconoscimento nei setting sanitari delle pazienti che sono state vittime di episodi di violenza (soprattutto se ripetuta) risulta dunque rilevante sia in fase di progettazione di politiche di prevenzione, sia al fine di indagare e valutare compiutamente la diffusione del fenomeno.
Il progetto di ricerca intrapreso, condotto congiuntamente da ricercatori del Dipartimento di Informatica dell’Università di Torino, del Servizio Sovrazonale di Epidemiologia dell’ASL TO3, e dell’Istituto Superiore di Sanità, si propone l’obiettivo di creare strumenti per l’automazione dell’analisi testuale delle cartelle cliniche di Pronto Soccorso al fine di individuare lesioni derivanti da episodi di violenza, in special modo violenza di genere. Obiettivo finale è quello di sviluppare un sistema che sia strumento di supporto al personale ospedaliero nella creazione di meccanismi di alerting per episodi di violenza non riferiti.
Violenza di genere: rilevanza e distribuzione regionale
La rilevanza del tema è testimoniata dall’insieme di dichiarazioni, convenzioni, piattaforme e piani che governi e entità sovranazionali hanno sottoscritto ed approvato negli ultimi decenni al fine di analizzare e contrastare il fenomeno [Dichiarazione di Pechino 1995, Convenzione di Istanbul 2011].
In particolare, la dichiarazione di Istanbul, sottoscritta dal nostro Paese il 27 settembre 2012, è il primo strumento internazionale giuridicamente vincolante che propone un quadro normativo completo e integrato a tutela delle donne contro qualsiasi forma di violenza. Tale strumento è stato ripreso ed esteso all’interno del Piano Strategico Nazionale sulla violenza maschile contro le donne 2017- 2020.
In estrema sintesi, questo documento è costituito da un insieme di provvedimenti su prevenzione, protezione e sostegno delle vittime, perseguimento dei colpevoli, politiche integrate, miranti a contrastare il fenomeno della violenza di genere. Alla base delle politiche pubbliche sono poste varie iniziative molto diverse, per esempio finalizzate ad aumentare la consapevolezza nella pubblica opinione sulle radici culturali del fenomeno; a istituire un numero verde, il 1522, per la segnalazione di episodi di violenza; a costruire percorsi di tutela per donne oggetto di violenza; a migliorare l’efficacia dei procedimenti giudiziari per perseguire i responsabili di questi reati e per aumentare le tutele nei confronti delle vittime di abusi e violenze.
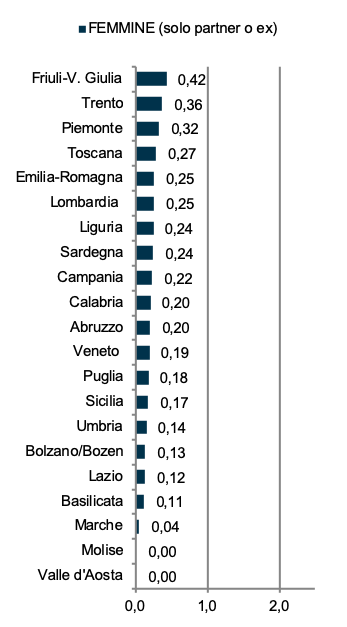 Come si evince dall’indagine della Commissione parlamentare di inchiesta sul femminicidio pubblicata nel marzo 2018 e contenente le percentuali di femminicidi negli anni 2012-2016, il fenomeno è distribuito in maniera sostanzialmente uniforme sul territorio nazionale. Il Piemonte è settimo in questa classifica, chiusa da Molise e Valle d’Aosta, uniche regioni in cui non si sono verificati femminicidi nel quinquennio di interesse. Normalizzando i dati per la numerosità della popolazione delle regioni, e restringendo l’indagine ai casi in cui il femminicidio è commesso da partner o ex [Dati ISTAT], si nota invece come il Piemonte sia ai primi posti tra le regioni con i tassi più alti di femminicidi commessi da partner o ex partner (tassi*100.000 residenti proposti nella Figura superiore). Tali dati mostrano una dimensione regionale del problema, particolarmente rilevante in Piemonte.
Come si evince dall’indagine della Commissione parlamentare di inchiesta sul femminicidio pubblicata nel marzo 2018 e contenente le percentuali di femminicidi negli anni 2012-2016, il fenomeno è distribuito in maniera sostanzialmente uniforme sul territorio nazionale. Il Piemonte è settimo in questa classifica, chiusa da Molise e Valle d’Aosta, uniche regioni in cui non si sono verificati femminicidi nel quinquennio di interesse. Normalizzando i dati per la numerosità della popolazione delle regioni, e restringendo l’indagine ai casi in cui il femminicidio è commesso da partner o ex [Dati ISTAT], si nota invece come il Piemonte sia ai primi posti tra le regioni con i tassi più alti di femminicidi commessi da partner o ex partner (tassi*100.000 residenti proposti nella Figura superiore). Tali dati mostrano una dimensione regionale del problema, particolarmente rilevante in Piemonte.
Il progetto: verso un sistema per l’analisi automatica delle cartelle di PS
Il progetto muove dall’idea che l’insieme di provvedimenti predisposti dal richiamato Piano Strategico Nazionale potrebbe essere completato da un meccanismo di alerting che permetta di tracciare e segnalare (oltre che studiare retrospettivamente, su base statistica)
in maniera preventiva, accessi in Pronto Soccorso (PS, nel seguito) causati da possibili comportamenti violenti. Queste le assunzioni alla base del progetto:
- gli accessi a PS sono predittori di eventi di femminicidio (è stato verificato statisticamente che i femminicidi sono spesso preceduti da accessi a PS);
- la violenza alla base delle lesioni riportate dai pazienti può non essere tracciata all’interno delle cartelle cliniche (per varie ragioni, fra cui la difficoltà per gli operatori di PS, anche per questioni di tempo, di riconoscere segni di violenza e annotare le probabili cause delle ferite riscontrate, oltre alla reticenza delle vittime);
- fra gli strumenti di prevenzione mancano meccanismi di riconoscimento che permettano di segnalare casi di possibile violenza con tempestività, eventualmente individuando relazioni tra accessi reiterati a PS ed evidenziando lesioni simili (e/o riconducibili a forme di violenza analoghe) negli accessi precedenti.
Il riconoscimento precoce di casi di violenza attraverso l’analisi automatica delle cartelle cliniche di PS può essere un elemento rilevante all’interno delle reti della sanità delle varie regioni.
Da un punto di vista informatico, l’analisi delle cartelle cliniche di PS (in particolare delle porzioni relative ad anamnesi ed esame obiettivo) mirante all’individuazione di episodi di violenza, costituisce un problema di classificazione binaria. Il sistema deve cioè distinguere casi di violenza (V) da quelli di non violenza (NV), come ad esempio incidenti domestici e stradali. Inoltre, si vorrebbe non solo risalire alla classe corretta (V/NV), ma anche estrarre informazioni rilevanti nella descrizione dell’eventuale episodio di violenza, quali gli attori (chi ha inflitto e subito la violenza), lo strumento o la modalità con cui la violenza è stata esercitata, il luogo, ed il distretto corporeo interessato. Questo tipo di problemi di classificazione è stato tradizionalmente risolto attraverso approcci di apprendimento supervisionato.
Gli algoritmi di apprendimento supervisionato sono una classe di algoritmi largamente utilizzati nell’ambito dell’intelligenza artificiale al fine di sviluppare sistemi in grado di apprendere funzioni di mapping. Informalmente, dato un insieme di esempi annotato con la categoria cui ciascun esempio appartiene, l’algoritmo apprende una funzione che permetta di classificare correttamente nuove (cioè non appartenenti agli esempi già visti) istanze del problema. Per esempio, dato un insieme di addestramento costituito da immagini in cui sono presenti o assenti delle biciclette, un sistema di apprendimento supervisionato può apprendere una funzione dalle immagini a un output, per classificare nuove immagini come contenenti o meno delle biciclette. Vari elementi concorrono alla bontà del classificatore appreso, migliorandone la capacità di generalizzazione: l’algoritmo di apprendimento utilizzato, la consistenza e la qualità dell’insieme di addestramento, la possibilità di elaborare più esempi etichettati correttamente (ad esempio, più biciclette si vedono, più si riesce ad astrarre da possibili varianti di ruote, manubrio e pedali), il bilanciamento del training set (nel caso di classificazione binaria sulla presenza/assenza delle biciclette dall’immagine, essendo idealmente augurabile avere un numero confrontabile di immagini con e senza biciclette), sono fra i fattori più rilevanti.
La prima fase dello sviluppo del sistema è consistita nella raccolta di dati annotati, in questo caso un insieme di documenti (Cartelle di Pronto Soccorso, CPS), alcuni dei quali
contenenti descrizioni di lesioni frutto di violenza, altri relativi a problemi non legati alla violenza. Tali documenti provengono da un progetto avviato presso l’Istituto Superiore di Sanità, il SINIACA-IDB (Sistema Informativo Nazionale Incidenti in Ambienti di Civile Abitazione – Injury DataBase). Tutti i dati sono anonimizzati e trattati nel rispetto della Direttiva (UE) 2016/680 del Parlamento europeo, relativa al trattamento dei dati personali.
I testi contenuti nelle CPS si sono rivelati in origine molto rumorosi: sono quindi stati pre-processati per rimuovere errori di battitura (es.: traum aarto), abbreviazioni e contrazioni varie (c.e. occhio dx.; rif algie al corpo). A tale fine è stato sviluppato un correttore specifico per il dizionario del dominio medico.
È quindi stato addestrato un classificatore bayesiano (un algoritmo probabilistico basato sull’applicazione del teorema di Bayes), un tipo di strumento largamente utilizzato in letteratura per task come la categorizzazione testuale. In una sperimentazione preliminare il classificatore, addestrato su un training set composto di circa 38,000 record (ciascuno contenente le informazioni presenti in anamnesi ed esame obiettivo presenti in una CPS), affinato tramite validation set composto di altri 9,000 record (distinti da quelli nel training set). Il set di dati su cui è stato valutato il classificatore appreso è composto di circa 9,000 record, distinti dai precedenti. Per la valutazione dei sistemi di questo tipo due misure molto utilizzate sono precision e recall, e la loro media armonica. La precision misura la proporzione di risultati corretti fra tutti quelli restituiti dal classificatore; mentre la recall misura quanti dei risultati corretti sono stati individuati dal classificatore. La loro media armonica (nota anche come F-measure) è una composizione delle due grandezze, che fornisce un indice sintetico per valutare l’accuratezza della classificazione. La precision ottenuta sperimentando sui 9,000 elementi oggetto di test è 0.69, mentre la recall è 0.91 (F-measure 0.78). Mentre la recall ottenuta è soddisfacente, una precision al 69% indica un ampio margine di miglioramento, in quanto al momento il 31% dei casi comporta un errore di classificazione (falsi positivi).
Abbiamo quindi raffinato il sistema introducendo due correttivi: uno per individuare automaticamente i termini più rilevanti (per esempio colpire, picchiare, pugno), ed uno per individuare strutture lessico – sintattiche comuni alle descrizioni di violenza (colpita/percossa/schiaffeggiata da convivente/compagno/persona conosciuta).
Per l’individuazione dei termini più salienti è stata adottata una misura nota in letteratura che permette di identificare i termini più frequenti (ovviamente non i più frequenti in assoluto, che sono congiunzioni, verbi ausiliari, articoli, preposizioni) e discriminativi a livello della collezione dei documenti (ciascun documento è rappresentato da un record di CPS, nel nostro caso). Per quanto riguarda l’individuazione delle strutture lessico-sintattiche significative, i testi delle CPS sono stati analizzati tramite un analizzatore sintattico (parser), che è un programma che si occupa di individuare in particolare i rapporti di dipendenza fra i token della frase, restituendo una struttura ad albero che descrive tali dipendenze. In questo modo il sistema ha avuto modo di attribuire un punteggio alle strutture sintattiche individuate che contengono termini salienti (in qualche modo evocativi di una descrizione di violenza, o di non violenza).
Come osservato, l’accuratezza del classificatore utilizzato in precedenza era bipartita: soddisfacente per quanto riguarda la capacità di individuare i casi di violenza (che nel 91% dei casi sono stati individuati correttamente), meno soddisfacente per quanto riguarda la precisione delle risposte (corrette al 69%): cioè fra tutti i risultati che per il classificatore contenevano lesioni frutto di violenza solo alcuni in realtà lo erano. Abbiamo quindi eseguito nuovamente gli esperimenti sullo stesso set di dati con la tecnica illustrata (cioè attribuendo un peso ai vari termini e ricercando strutture che tipicamente esprimono lesioni frutto di violenza al fine di supportare il classificatore nel riconoscimento dei record le cui lesioni sono frutto di violenza): i risultati sul test set (cioè su un insieme di dati non precedentemente analizzati dall’algoritmo in fase di addestramento e tuning dei parametri) sono caratterizzati da una recall più bassa (0.87), ma da una precisione significativamente migliorata (0.87); la F-measure risultante è ovviamente 0.87.
Conclusioni: dal prototipo software all’uso nel mondo reale
Attualmente è in fase di sviluppo una riscrittura del sistema, per renderlo più robusto —per trattare ulteriori fenomeni linguistici— e modulare, così da semplificarne l’interfacciamento con altri moduli software. La ricerca verte sull’adozione di strumenti di classificazione basati su paradigmi e architetture completamente differenti da quelli fin qui adottati (basati su un algoritmo probabilistico molto performante ma datato e dunque, verosimilmente, migliorabile). Ulteriori esperimenti, e su insiemi di dati più consistenti, sono quindi ancora necessari per migliorare il prodotto informatico di questo progetto e rendere il prototipo attuale un prodotto maturo.
Siamo però consapevoli del fatto che l’adozione e la diffusione di uno strumento come il sistema descritto non sono solo legate alla funzionalità tecnica, che naturalmente resta prerequisito irrinunciabile. Altri fattori sono potenzialmente rilevanti. Per esempio, il riconoscimento (da parte dei livelli dirigenziali, in particolare con responsabilità di progettazione dei sistemi informativi) del sistema descritto come strumento di indagine valido per tracciare tempestivamente il fenomeno della violenza di genere. Sul campo, la diffusione del sistema è connessa al grado di coinvolgimento e accettazione da parte dei suoi potenziali utenti, nei reparti di Pronto Soccorso.
In sintesi, gli sforzi futuri riguarderanno in eguale misura il raffinamento del prototipo e la creazione di una rete sociale di professionisti, operatori sanitari e centri antiviolenza che contribuiscano al progetto fornendo spunti in termini di funzionalità (con nuovi requisiti, inizialmente non considerati), e che siano interessati a utilizzare il sistema integrandolo all’interno dei software attualmente in uso. Il progetto è open, nel senso informatico dell’apertura a nuovi contributi, e dell’apertura a una comunità, auspicabilmente ampia e differenziata, interdisciplinare, intenta a trattare il problema della violenza di genere.
a cura di Davide Colla, Enrico Mensa, Daniele P. Radicioni – Dipartimento di Informatica, Università di Torino; Carlo Mamo – Epidemiologia ASLTO3; Alessio Pitidis – Dipartimento Ambiente e Salute, ISS
fonte: DORS




