
Come distribuire meglio 80 euro
La nostra vita quotidiana è sempre più assistita da computer che, attraverso sofisticati algoritmi di machine learning, facilitano lo svolgimento dei compiti più disparati. Facebook, per esempio, ci aiuta a ritrovare vecchi amici proponendoci una lista di persone che potremmo conoscere, almeno secondo le informazioni disponibili sulla piattaforma.
Gli algoritmi possono anche contribuire a migliorare le politiche pubbliche. Un ambito di applicazione è quello dei sussidi o trasferimenti pubblici: il machine learning può essere usato per predire a quali famiglie o imprese sarebbe preferibile indirizzarli per conseguire un determinato obiettivo. Due esempi ci aiutano a capire come.
Nell’assegnare un trasferimento monetario alle famiglie, il decisore pubblico potrebbe voler massimizzare l’effetto sui consumi. È il caso degli 80 euro. Un modo per farlo è selezionare i nuclei con maggiori vincoli alla capacità di spesa, che in teoria dovrebbero essere più propensi a consumare. La condizione è però osservabile solo in alcuni studi, come l’Indagine sui bilanci delle famiglie della Banca d’Italia che misura la capacità delle famiglie di arrivare a fine mese. Per indirizzare il bonus a beneficiari con maggiore propensione al consumo occorre quindi predire la condizione di “difficoltà nell’arrivare a fine mese” sulla base di informazioni che sono disponibili in archivi amministrativi e che sono note al decisore pubblico al momento dell’assegnazione del trasferimento.
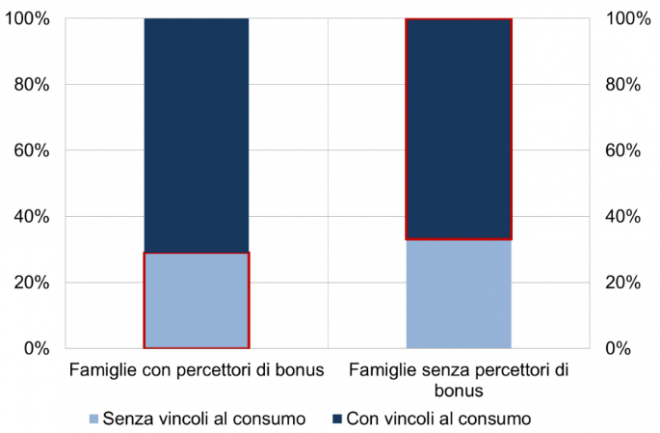
In un recente lavoro, usiamo il machine learning a questo scopo. L’algoritmo, denominato decision tree, fornisce una predizione delle famiglie con vincoli alla capacità di spesa sulla base di alcune variabili (riferite principalmente al loro reddito e alla loro ricchezza; figura 1) che il decisore pubblico potrebbe utilizzare per assegnare il bonus. Ad esempio, le famiglie che hanno attività finanziarie inferiori a 13.255 euro e reddito disponibile sotto i 36.040 euro sono tra quelle a cui verrebbe assegnato il bonus. L’utilizzo dell’algoritmo al posto della regola oggi in vigore, basata solamente su soglie di reddito individuale, permetterebbe di meglio individuare i destinatari del sostegno. Si può calcolare che circa un terzo delle famiglie che hanno beneficiato del bonus non aveva – verosimilmente – vincoli al consumo, mentre circa due terzi di quelle non beneficiarie li aveva (figura 2).
Figura 1 – Modello di previsione del decision tree per la condizione di famiglia con vincoli al consumo
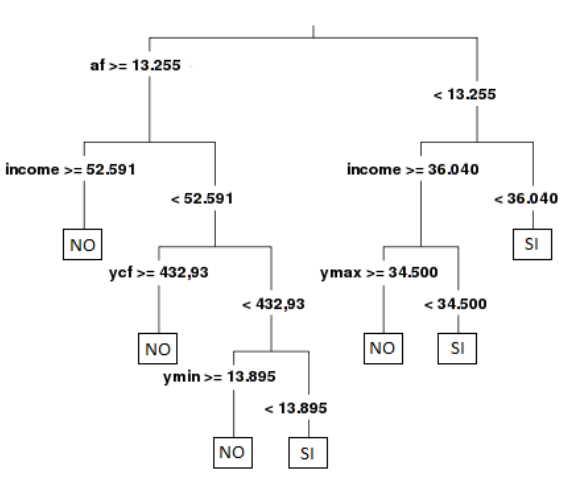

Figura 2 – Percentuale di famiglie predette con vincoli al consumo suddivise in base alla percezione del bonus
Il Fondo di garanzia per il credito
Il secondo esempio riguarda le garanzie pubbliche per l’accesso al credito bancario, che dovrebbero essere rivolte alle imprese solvibili (altrimenti non sarebbero in grado di restituire il finanziamento alle banche e le perdite verrebbero sostenute dal settore pubblico), ma con difficoltà di accesso al credito (che, quindi, molto probabilmente non riceverebbero prestiti senza la garanzia). I sistemi di garanzia pubblica che già esistono si limitano invece a escludere i debitori con scarsa affidabilità creditizia. Anche in questo caso può venire in soccorso un algoritmo. In un altro nostro lavoro proponiamo un meccanismo per regolare l’accesso alla garanzia che si basa su un algoritmo (chiamato random forest) che predice quali sono le imprese affidabili, ma con maggiori difficoltà a ricevere finanziamenti dal settore bancario. In base all’algoritmo, solo il 60 per cento delle aziende che hanno beneficiato del Fondo di garanzia nel 2012 avrebbero dovuto accedervi. E la maggioranza delle imprese che non avrebbe dovuto ricevere la garanzia non ha difficoltà di accesso al credito.
Valutazione sempre necessaria
Come non sempre chi ritrova un amico (grazie a Facebook) trova un tesoro, così anche nel caso delle politiche pubbliche va capito se sia una buona idea individuarne i beneficiari sulla base degli algoritmi. Per farlo occorre una valutazione a posteriori, basata su metodi controfattuali (come d’altronde dovrebbe sempre essere per le politiche pubbliche). Nel caso del Fondo di garanzia, ad esempio, va dimostrato che, tra le imprese che hanno effettivamente ricevuto la garanzia, l’andamento dei prestiti bancari sia stato migliore per quelle che avremmo selezionato usando machine learning. Nel nostro lavoro mostriamo come ciò sembri essere vero, sia attraverso semplici confronti, sia utilizzando un metodo di valutazione più robusto (un regression discontinuity design).
L’utilizzo del machine learning avrebbe quindi permesso un sostanziale miglioramento dell’efficacia delle politiche, a parità di risorse pubbliche impiegate (oppure una significativa riduzione della spesa, a parità di effetti).
Una questione molto dibattuta riguarda l’interpretabilità della regola decisionale. Può non essere un’operazione agevole, specie per gli algoritmi più complessi, come ad esempio il random forest. Va però considerato che l’utilizzo di un algoritmo predittivo ci permette di incorporare già nella regola di accesso al beneficio considerazioni esplicite circa l’obiettivo che si vuole raggiungere. In altri termini, è vero che può essere meno banale capire a chi vanno gli aiuti pubblici, ma è sicuramente più chiaro qual è lo scopo del decisore pubblico (ovviamente a patto di rendere noti i dettagli relativi all’analisi che ha guidato la scelta dell’algoritmo).
Come ogni regola di selezione dei beneficiari di una politica pubblica, anche quelle ottenute con il machine learning individuano gruppi specifici (i target) a discapito di altri. La selezione è finalizzata a raggiungere un determinato obiettivo, ma potrebbe contrastare con altre finalità. Il decisore pubblico potrebbe, ad esempio, essere interessato tanto alle questioni di efficienza quanto a quelle di equità. L’utilizzo effettivo degli algoritmi potrebbe quindi richiedere alcuni accorgimenti per tenere conto anche di questi aspetti.
* Le opinioni qui espresse sono quelle degli autori e non riflettono necessariamente quelle della Banca d’Italia.
fonte: lavoce.info




